GLES API
- 所有OpenGLES2.0实现必须至少支持8个 vertex attribute。可用
glGetIntegery(GL_MAX_VERTEX_ATTRIBS, &maxVertexAttribs)查询实际数目。 - constant vertex attribute 在一个图元的所有顶点上都是相同的,所以只需要一份。通常使用
glVertexAttrib*f*进行传值。 - vertex array 用于逐顶点指定属性数据,缓存在host的地址空间(client空间)。使用
glVertexAttribPointer指定数据读取位置与大小。(本质上是个存于CPU主存的指针)此处可以做的优化有二,一是根据需要合理组织顶点属性数据的结构;而是根据需要尽可能降低数据格式的大小。 - host这边的数据要与shader里面的attribute变量绑定,需使用
glBindAttribLocation(GLuint program, GLuint index, const GLchar *name),其中,program指具体某个program对象的名字,index就是glVertexAttrib和glVertexAttribPointer的第一个参数,name就是shader里面用attribute声明的变量名。 glGetAttribLocation(GLuint program, const GLchar *name)可以通过name查找与之绑定的index。- 顶点数据起于host内存空间(CPU),每次绘制(glDrawArrays/glDrawElements)时,都会将数据复制到图形内存空间(GPU)。显然,这样会浪费大量的计算力在数据传输上,浪费内存带宽,浪费电。所以,把部分数据缓存在GPU端(显存),可以提高性能,显著降低带宽占用和耗电量。Vertex Buffer Object(VBO)应运而生。
- OpenGLES支持两种VBO,
array buffer objects和element array buffer objects,前者用GL_ARRAY_BUFFER标识,缓存顶点数据,后者用GL_ELEMENT_ARRAY_BUFFER标识,缓存图元的索引。 - VBO三件套:创建-绑定-传数据,
glGenBuffers-glBindBuffer-glBufferData(glBufferSubData) - 对于静态几何体,数据传递给GPU之后,host端的数据可以删除释放掉,节省内存。
- OpenGLES三图元:triangle,line,point。相关绘制模式:GL_POINTS GL_LINES GL_LINE_STRIP GL_LINE_LOOP GL_TRIANGLES GL_TRIANGLE_STRIP GL_TRIANGLE_FAN。
- OpenGLES图元绘制两方法:glDrawArrays 和 glDrawElements。
- 别废话了,能用VBO就赶紧上,能用
glDrawElements就别用glDrawArrays。 - glPixelStorei设置的打包/解包对齐参数是全局状态,不只是作用某个单独的纹理对象。
- 由于GPU的并行架构,shader中的条件判断最好是常量表达式,以防出现结果不一致。
- VS中能利用的uniform变量具有数目限制(>=128,具体限制看实现)。各类常量均会占用计数。有时相同的字面常量会计数多次(比如,多次使用
1.0,会计数多次,而不是一次)。所以shader中最好将字面常量转为#define或const形式。 - Texture是一个Object,而不仅是一块图像数据。它更像一个容器(结构体),里面包含了用于渲染所需的数据,主要有
图像数据、filter模式、wrap模式。
GLSL
- uniform:host传递给着色器的只读值,存储于常量空间,被顶点着色器和片段着色器共享。
- attribute:host传递的顶点属性,也是只读值,且只能用于顶点着色器,比如顶点位置、颜色和贴图坐标之类的属性值。
- varying:VS的输出,FS的输入;用于VS向FS传递数据,须在两个shader中有一样的声明。
- VS内置变量:
gl_Position,gl_PointSize,gl_FrontFacing。 - gl_Position:输出顶点的裁剪空间坐标,用于裁剪空间转屏幕空间。是
highp精度的浮点数。 - gl_PointSize:指定point sprite的像素大小。是
mediump精度的浮点数。 - glFrontFacing:这个变量不会在VS里直接赋值。是根据VS生成的position值和渲染的图元类型自动决定的。是个boolean值。
- 默认
float和int的精度都是highp。一般在VS里都是用默认的高精度。 for循环里面的索引,不能在循环体里面变化,只能在for()里面。而while和do-while虽然属于规范,但不一定实现了。
Optimization
- 对于高级光照与阴影,尽可能将逐像素(per-pixel)计算换成逐顶点(per-vertex)计算,或者直接使用光照贴图;同理,高光、cube light还有反射映射都可以预烘培在原始纹理中。阴影也一样。
- 有些无法完全展示的大场景,最好细分一下三角形,虽然总的三角形增加了,但GPU可以有效的裁剪掉不需要绘制的三角形,可以提升性能。
- 避免不必要的
eglMakeCurrent调用 - 移动端pixel shader稀缺,实现一个多级着色(level-of-shading)显得很有必要;原理和LOD类似,根据离摄像机距离的不同选用不同复杂度的shader进行着色。
- 降低GL状态切换:1)ES API会分发给驱动在内核态中的那部分,再转发给GPU;所以不要滥用API;2)纹理切换耗性能,所以对于渲染调用,最好先按
texture排序,再按state vector排序。 - 降低Draw call:进行一次draw call需要太多的前置操作,比如清空上个状态、处理当前绑定的VAO、从主存复制数据到GPU等等。所以,谨记 没有消耗就没有损失。
- 分辨率缩放:利用FBO将场景渲染成小分辨率,然后在post-process阶段进行缩放到设备真实分辨率。UI和HUD可以直接以设备分辨率进行渲染。
- 对于常用的模糊特效,一般用的高斯算法,优化点有俩:1)将偏移点的计算从pixel shader移到vertex shader或者CPU中去;2)从低mipmap采样,应用模糊之后再缩放回去。
- 利用纹理fetch的高效性,可以设计精巧的算法来代替直接的算数运算。(这个技巧性太高,需要静心设计数据放置在纹理中,一次纹理采样等于多次普通计算)
- 背面裁剪,特别是不透明物体,非平面(点、线)对象
- 使用LOD,一般在网格的多边形上使用较多,其实在shader effect上使用也是效果明显
- 使用VBO代替VA,因为VA会在每一个draw call时复制顶点数据,浪费带宽影响效率
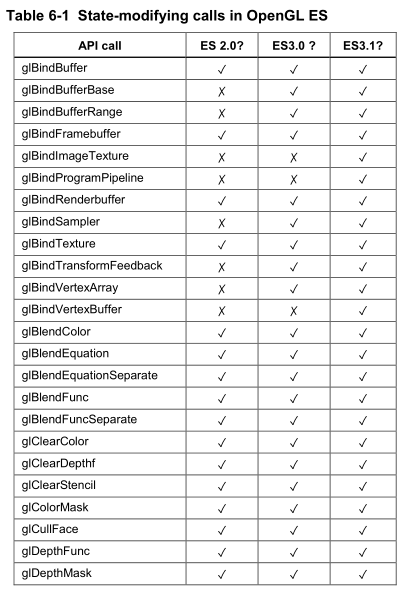
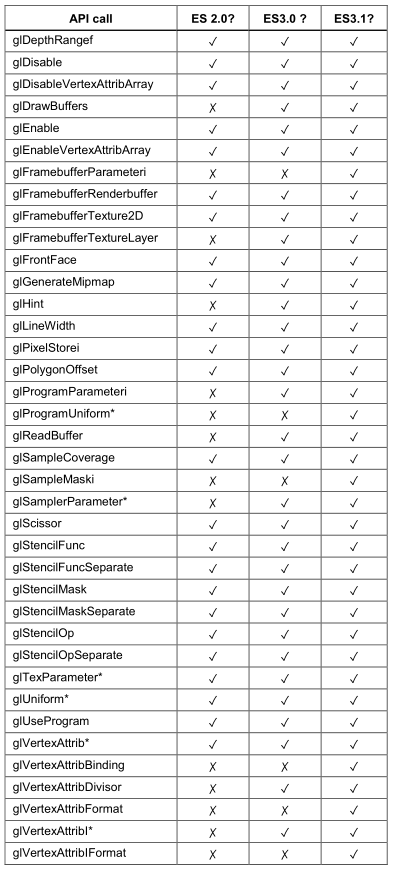
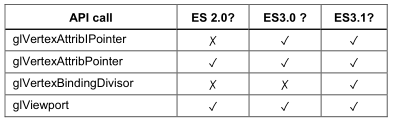
- 下面列出会引起状态改变的API,记得不要滥用:
- 对drawcall排序可以有效降低状态切换的次数。可以遵循下面的排序规则:
1、按 render target 排序:RT之间的切换消耗太高,一般不要做这种事(调用 `glBindFramebuffer、glFramebuffer*)。如果一个对象需要使用多种program在多个RT上绘制,那顺序肯定是先在program之间切换,在切换RT(逐个RT绘制过去);
2、按 program 排序:同一个frame buffer里面,尽量降低program的切换。假设一个场景三个物体,两个使用相同的FS,肯定是这两个物体挨着渲染较好;
3、其他:比如纹理切换,顶点数据变化之类的。
- shader代码中,使用最恰当的数据类型,避免做耗时的类型转化(type casting)
-
标量打包进向量,标量运算转化成向量运算
- 高效的采样纹理:
1、避免随机访问:硬件一般同时处理2*2的片元块,所以shader访问同一个块中的相邻纹素会比较快
2、少用3D纹理:当前读取体素的操作还是比较耗性能的
3、单个shader纹理采样上限:一般单个shader里使用4个sampler就是极限了,再多会造成性能狂降
4、纹理压缩:降低内存占用,降低数据传输
5、使用mipmap:在号内存的地方可以提高性能
- 少用分支判断:分支判断非常影响性能,能不用就不用。如果一定要用,判断条件的选择非常重要。优先顺序下:1)常量,编译期间确定的值;2)uniform 变量;3)shader中可更改的变量。使用常量做条件判断性能影响还可以接受。
- 尽可能节省shader指令,一条都不能浪费。
- 不要在shader里做数学计算并保存成常量,移到CPU端去做
- 不要在片段着色器中尝试丢弃一些像素,看起来会有性能提升,但实际上如果在多线程中,只要有某个线程在使用该像素,那shader还是会执行。而且,你做的丢弃操作还依赖shader编译器是否生成了对应的字节码。理论上,如果某个线程上的所有像素均被丢弃,GPU极有可能停止处理该线程;而实际上,丢弃操作会禁用硬件优化,得不偿失。
- 同理,不要在片段着色器中修改深度值,这也会禁用硬件优化。
- 避免在VS中做纹理fetch,而且只操作压缩纹理数据。
- 在Adreno上,16bit的精度(mediump)相比 32bit精度(highp),拥有两倍的速度,还节省一半的消耗。所以,最好默认
precision mediump float,即使遇到需要高精度的情况,比如纹理坐标采样,也可以按需避免。 - 最大化的将逐片段计算转移到到顶点计算中,毕竟顶点数明显少于片段数。
- 带宽优化:说白了就是减少数据传输的消耗。常见的操作就是压缩传输数据量和 减少传输次数(缓存) 。当然,缓存不是无限的,出现 cache miss 就不可避免,只能采取措施尽量降低失效的频率。
降低缓存失效概率:
1、提升传输速率:避免在drawcall中使用客户端顶点数据缓存,最好从不使用
2、降低GPU执行drawcall时需要的数据量
减少传输的数据量:
1、使用压缩纹理:压缩纹理不仅减少内存,减少总传输量。更重要的是,当前压缩纹理都是4x4块压缩。这样纹理一个fetch指令能取出16个纹素,而不是一般纹理的1个纹素。由于纹理数据的连贯性,配合当前移动设备主流的Tiled Render,可能这一个指令就满足了渲染数据的需求。
2、打包顶点数据:顶点数据结构好好排列一下,选择合适的数据结构,不出现空洞,一个bit都不浪费。
3、采用索引模式的drawcall:绘制的时候使用index,别老是把顶点本身传来传去的。
Think
Refrence
- OpenGLES 2.0 Programming Guide
- Qualcomm Adreno OpenGL ES Developer Guide
- ARM Mali GPU OpenGL ES Optimization Guide